7月19日晚财联社报道,玛格丽特·阿特伍德、詹姆斯·帕特森和强纳森·法兰森等8000多名作家签署一封信,要求微软、Meta Platforms和Alphabet等公司领导者不要在未经许可或未支付报酬的情况下使用这些作家的作品训练AI系统。这封信由专业组织作家协会发表,写给了OpenAI、IBM、Stability AI和几家科技公司的首席执行官,这些公司运营着Bard、ChatGPT和Llama等AI模型和聊天机器人。
信中说:“数以百万计受版权保护的书籍、文章、散文和诗歌为AI系统提供了‘食物’,这些无穷无尽的‘大餐’却没有任何账单。你们花费数以十亿美元计的资金开发AI技术。你们使用我们的作品应该支付补偿,这样才是公平的,没有这些作品,AI将是平庸和非常有局限性的。”
美国作家协会报告显示,去年美国全职作家的收入中位数为2.3万美元(约合人民币16.5万元)。从2009年到2019年,作家的收入下降了42%。在作家签署的联名信曝光后,AI系统训练数据的确权和费用问题引发热议。
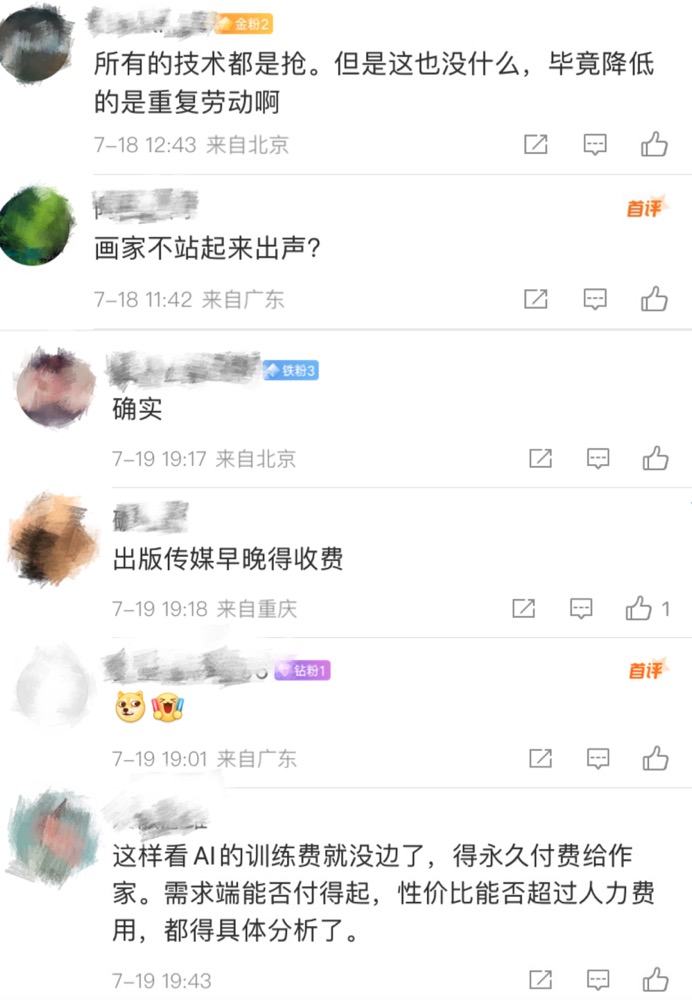
在消息评论区网友们呈现出不同观点,有人表示确实要支持作品付费,还呼吁画家站起来出声;但也有人表示技术升级是为了降低劳动重复,如此AI的训练费没边了,需要永久给作者付费,需求端能否支付得起,性价比能否超过人力费用,都需要具体分析。
众所周知,AI训练离不开海量数据的训练,而在人工智能的发展过程中,数据的确权、定价和交易一直是寇需解决的问题,国内外相关部门也在这方面持续优化相关法律法规。近日,我国国家网信办联合七部门印发《生成式人工智能服务管理暂行办法》明确了训练数据处理活动和数据标注等要求;生成式人工智能服务提供者应当采取有效措施防范未成年人用户过度依赖或者沉迷生成式人工智能服务,并生成内容进行标识等。